导航
简单有效
药物化学
MCAL
simulink
制图综合
zookeeper
监控
csdn热榜
CAS原子锁
ThingsBoard
flyfish
ts
敖丙
训练数据
企业人行
日期类的实现
firefox
clipStudioPaint
plugin
PPO
2024/4/13 9:05:58
强化学习系列之Policy Gradient算法
一. 背景
1.1 基础组成部分 强化学习里面包含三个部件:Actor,environment,reward function Actor : 表示角色,是能够被玩家控制的。 Policy of Actor:在人工智能中,Policy π \pi π 可以表示为一个神经网络,参数为 θ \theta

RL 实践(7)—— CartPole【TPRO PPO】
本文介绍 PPO 这个 online RL 的经典算法,并在 CartPole-V0 上进行测试。由于 PPO 是源自 TPRO 的,因此也会在原理部分介绍 TPRO参考:张伟楠《动手学强化学习》、王树森《深度强化学习》完整代码下载:8_[Gym] CartPole-V0 (PPO) 文…

百度工程师浅析强化学习
作者 | Jane 导读 本文主要介绍了强化学习(Reinforcement Learning,RL)的基本概念以及什么是RL。强化学习让智能体通过与环境的交互来学习如何做出决策,以获得最大的累积奖励。文章还介绍了策略梯度(Policy Gradient&a…

PPO 跑CartPole-v1
gym-0.26.2 cartPole-v1 参考动手学强化学习书中的代码,并做了一些修改 代码
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdmclass PolicyNet(nn.Module):def __…

机器学习:增强式学习Reinforcement learning
收集有标签数据比较困难的时候同时也不知道什么答案是比较好的时候可以考虑使用强化学习通过互动,机器可以自己知道什么结果是好的,什么结果是坏的
Outline 什么是RL Action就是一个functionEnvironment就是告诉这个Action是好的还是坏的
例子 Space i…
机器学习——PPO补充
On-policy vs Off-policy 今天跟环境互动,并学习是on-policy 只是在旁边看,就是Off-policy 从p中选q个重要的,需要加一个weight p(x)/q(x) p和q不能相差太多 采样数太少导致分布差很多,导致weight发生变化
On-Policy -&g…
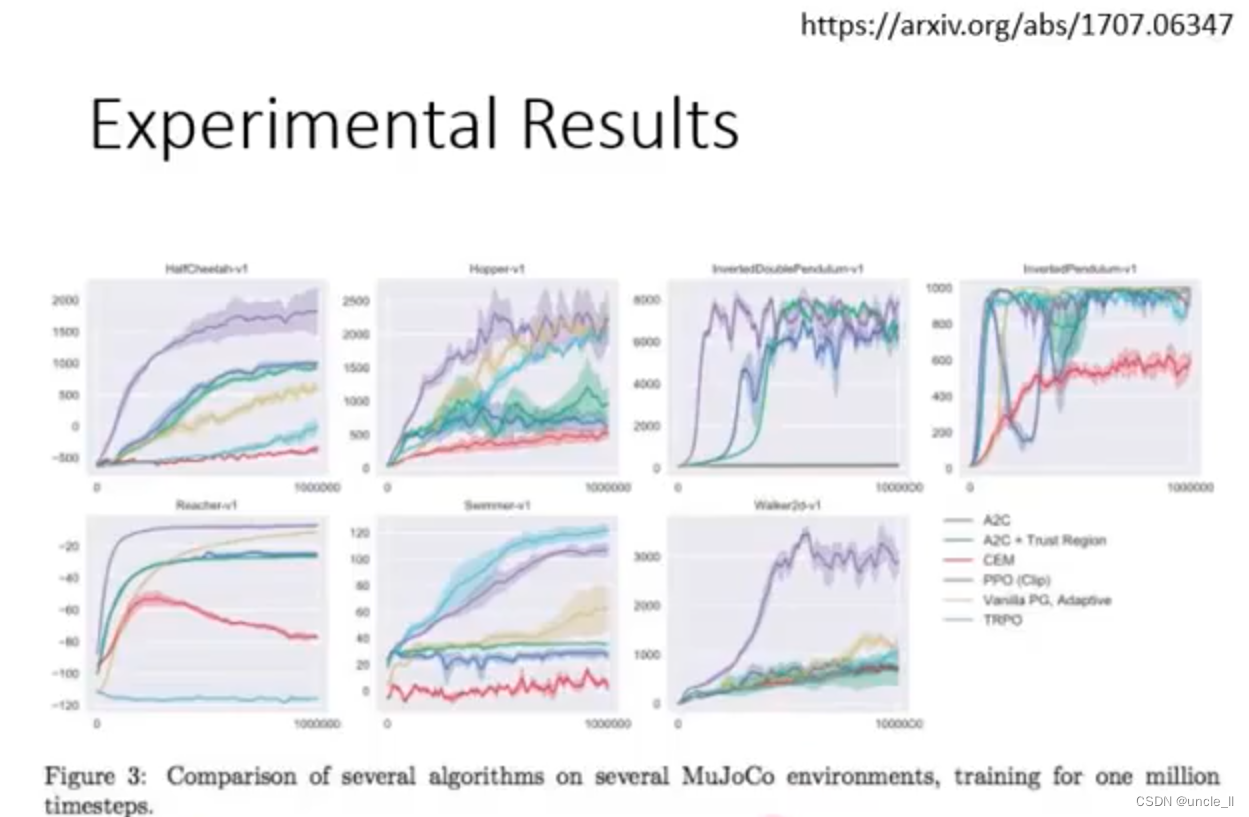
强化学习(9):TRPO、PPO以及DPPO算法
本文主要讲解有关 TRPO算法、PPO 算法、PPO2算法以及 DPPO 算法的相关内容。 一、PPO 算法
PPO(Proximal Policy Optimization) 是一种解决 PG 算法中学习率不好确定的问题的算法,因为如果学习率过大,则学出来的策略不易收敛&…
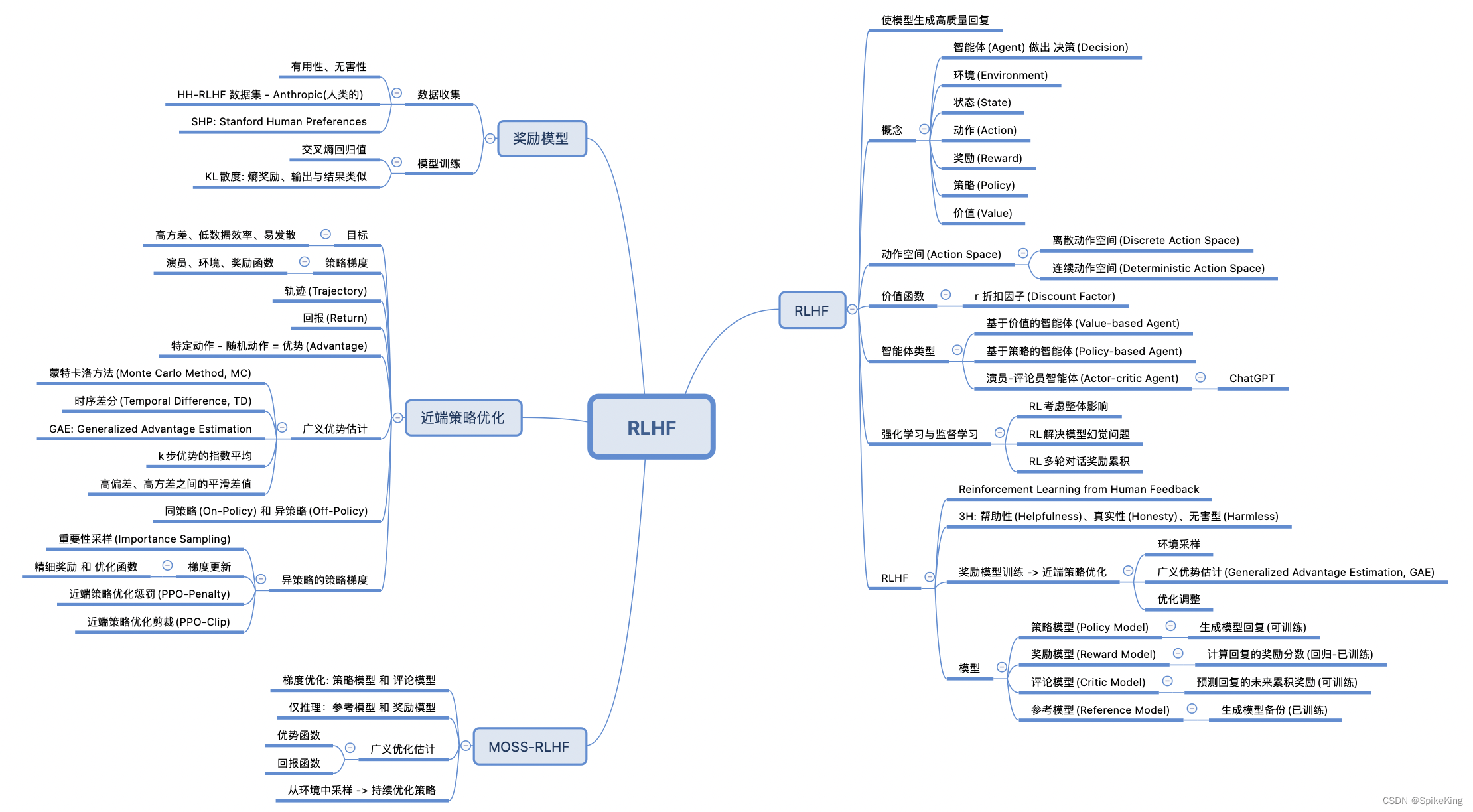
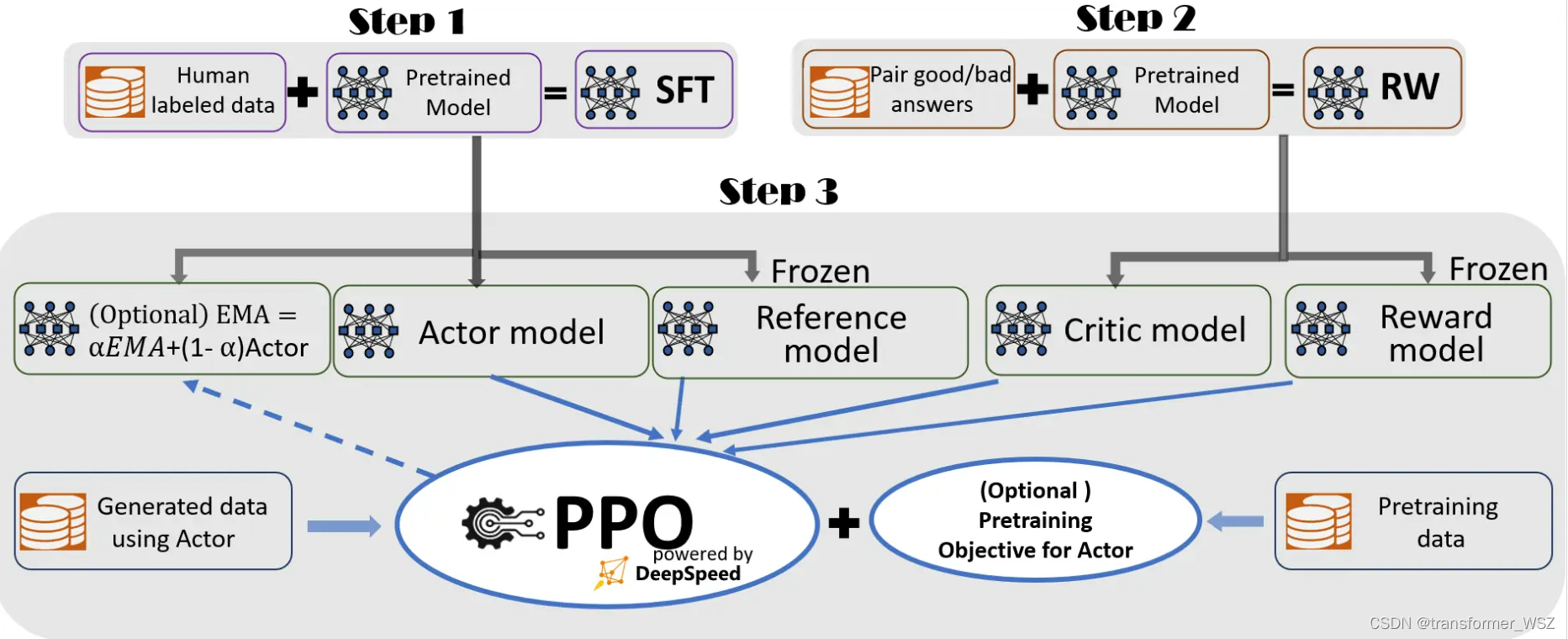
LLM - 大语言模型 基于人类反馈的强化学习(RLHF)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137269049 基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback),结合 强化学习(RL) 和 人类反馈 来优化模型的性能。这种方法主要包…

大规模语言模型人类反馈对齐--PPO算法代码实践
在前面的章节我们已经知道,人类反馈强化学习机制主要包括策略模型、奖励模型、评论模型以及参考模型等部分。需要考 虑奖励模型设计、环境交互以及代理训练的挑战, 同时叠加大语言模型的高昂的试错成本。对于研究人员来说, 使用人类反馈强化学…

ppo.py的bug
no cupy的问题后来是把ppo.py里的gpu相关的两处代码删除以后解决的,但是又出现了新的问题:TypeError: a bytes-like object is required, not ‘NoneType‘
但是我在跑chainerrl的ppo的时候也出现了no cupy的问题,记得是用conda install cup…